What is RAG?
For those are are emerging into the AI space later than others - like myself - I found the prospects and Retrieval-Augmented Generation (RAG) to be a great capability. RAG is not new but it connects from of the underlying AI magic to decision making that makes sense.
The missing piece? Context/Background.
Retrieval-augmented generation in Language Models (LLMs) is a framework that combines the capabilities of both retrieval models and generative models to improve the quality and relevance of generated text. This approach aims to enhance the generation process by incorporating information retrieved from external sources during text generation.
Why does this peak my interest?
If you’ve read my previous article about my new AI Coding Assistant - Tabby - then you know that I am actively running experiments to try and find both subjective and objective ways to compare how well different tools and models perform with code generation.
Sometimes it is laughable - but more often than not, it speeds up my productivity by a good amount by cutting out “fluff” tasks like traversing a directory tree or generating a random string.
With Tabby on the StarCoder-3B model, I’ve been super impressed with the results. The generation of code is very quick and often close enough to accept the suggestion and tweak.
Enter RAG
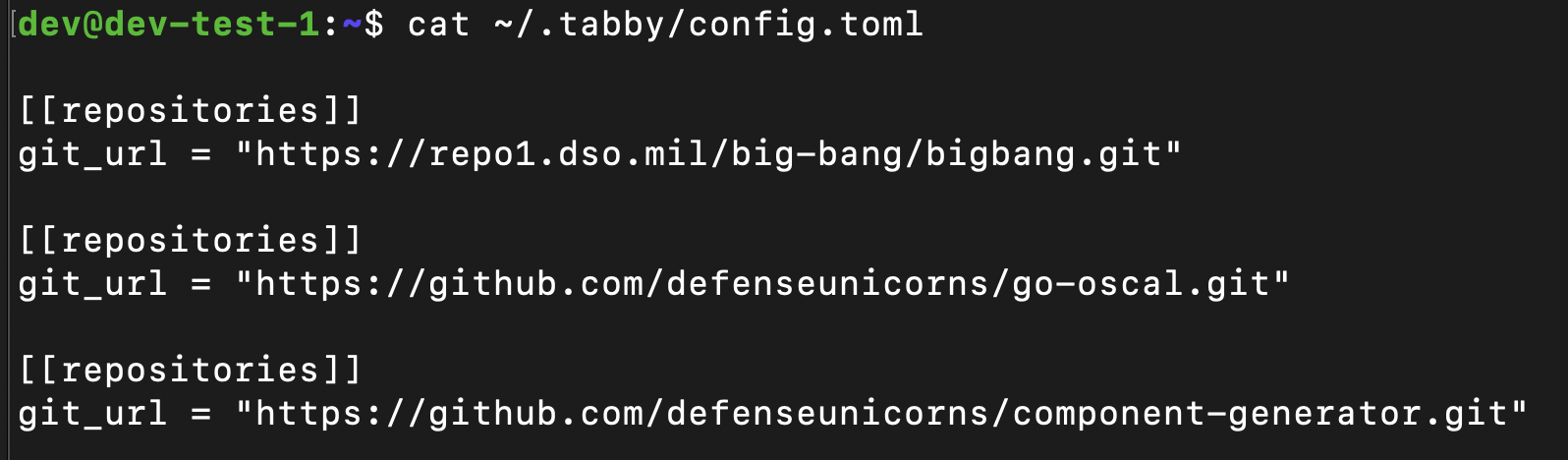
As of 10/15/23 - Tabby supports RAG through a configuration file in the persistent data location of your deployed instance.
As you can see, the configuration file is very simply. Simple append repositories that you want to use for code generation. This makes sense right? Much of the code i’m writing currently is within a shared domain of tools and datatypes. Now, Tabby can generate code with context of these repositories.
Backing up a step - Let’s deploy our own
You have two options for deploying Tabby on your own hardware. CPU or GPU based.
For myself, I had an RTX 2080 sitting in one of the machines in my hypervisor cluster idle - might as well put it to good use.
dev@dev-test-1:~/tabby$ cat docker-compose.yaml
version: '3.5'
services:
tabby:
restart: always
image: tabbyml/tabby:latest
command: serve --model TabbyML/StarCoder-3B --device cuda
volumes:
- "$HOME/.tabby:/data"
ports:
- 8080:8080
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
Provided you are connected to the internet, you can configure:
- The image you want to use
latestis shown here to allow for copy/paste - but an explicit tag is better.
- The model you want to use
- TabbyML/StarCoder-3B is pictured here and will be downloaded from the internet upon startup.
Running the container
Simply run docker compose up -d and you’ll have an operational instance of Tabby running and available to connect.
IDE Connection
I’ll leave this one to the official docs - as they’ll be maintained more than this point in time blog post.
https://tabby.tabbyml.com/docs/extensions/
I use VSCode and the official extension for Tabby was easy to install and configure.
RAG Setup
As you can see in the configuration above, my persistent data is stored at $HOME/.tabby. We can create a config.toml in that directory with the repositories we want Tabby to index.
Once done, you need to run the scheduler:
docker exec -it tabby-tabby-1 /opt/tabby/bin/tabby scheduler --now
After that, you are all set to get down to building!
Next Steps
This capability is a huge enabler for software development. As I get some free time I’ll be working on a portable and air-gap friendly package of Tabby. Docker containers on a host with compose is great and all - but there is much more here that can be done to make Tabby and LLM’s more friendly to disconnected environments. Also including security guardrails that we find common with orchestration to-date like network isolation, etc.
If you are already building something similar or are interested in collaborating - please reach out!